Welcome to NexusFi: the best trading community on the planet, with over 150,000 members Sign Up Now for Free
Genuine reviews from real traders, not fake reviews from stealth vendors
Quality education from leading professional traders
We are a friendly, helpful, and positive community
We do not tolerate rude behavior, trolling, or vendors advertising in posts
We are here to help, just let us know what you need
You'll need to register in order to view the content of the threads and start contributing to our community. It's free for basic access, or support us by becoming an Elite Member -- see if you qualify for a discount below.
-- Big Mike, Site Administrator
(If you already have an account, login at the top of the page)
Broker: NT Brokerage, Kinetick, IQFeed, Interactive Brokers
Trading: ES
Posts: 159 since Dec 2014
Thanks Given: 40
Thanks Received: 166
Hey Greg, been a while.
Yes, I have used PostgreSQL and it's what I've decided on for my custom platform. It crushed everything else I tested. It is truly enterprise grade. For a tick store, I couldn't find anything faster.
Will agree with @Jasonnator - PostgreSQL has the same perf like a top most db system from IBM or MS.
But. The key advantages of "Big" databases - to provide flexible analytics and data mining features. Especially with big data. It is not enough just to make a fast system - all db has almost the same performance for primitive queries. The system should provide something more.
Good news - for trading it almost useless. No really. Most of all operations - select batch (for example, to do some backtesting) or updating toxic data. Or put the newest rowset. That is all!
In out app Hydra we started from DB (SQL Express was as underlying storage). But it shown us extremely poor performance in compare with file system. Maybe it will be faster with using some features like Clustering DB, but what the price for that?
Also one of the major questing - who will be use a trading app. If company - it is no any problem to maintain the db by special team. In case of one-man band" any human readable format like CSV can give odds to any DBMS - easy to read, supported by Excel, easy to load to any programming language, easy to modify (just open in Notepad and move forward).
Hi Jason, can you elaborate a bit on your data request schema as well as current storage capacity req'd and where it's stored (home PC and/or cloud e.g. AWS)?
Also, if you're using a home server, what's your hardware specs (HDD capacity total, RAM, CPU)?
My developer for a backtesting & live trading bot has elected to use PostgreSQL as well, per my indication that I'd like to store tick-level data for 3 months' worth across 30 U.S. futures instruments (plus 8-10 years of 1-hour OHLC bars). I figured <10TB of total storage capacity needed, but the real cost (>$300/mo) shows up due the total monthly up/down transfer quota between a colo'd server and a cloud solution like AWS. So, now we're looking toward a home server.
This is not completely accurate. Databases like Berkeley DB (BDB) are specifically about starting with the primitives, designing the underlying record format, and implementing everything around that (including the level of abstraction needed and even if relational type support is needed). Typical RDBMS like Postgres, Oracle, or MySQL have that design baked in based on the underlying storage formats provided by the software.
This is important for things like tick data whereby storage per tick is of pretty big importance and can have a direct bearing on performance (the more data that can fit in memory and/or the less backing store needing to be seeked, the better).
Broker: NT Brokerage, Kinetick, IQFeed, Interactive Brokers
Trading: ES
Posts: 159 since Dec 2014
Thanks Given: 40
Thanks Received: 166
I'll apologize in advance because my answer will be somewhat vague but that's due to a proprietary schema which I cannot disclose. I will say that I did testing on everything from an ancient Q6600 to i7 2600K to some fairly esoteric Xeon systems. Surprisingly, we learned the most from the much older and slower systems. The new hardware is just so blazing fast that some optimizing is not as easily discernable. Now obviously certain metrics must be interpreted in the context of system limitations and bottlenecks.
A solid understanding of instructions, clock cycles, fetching, pre fetching, cpu registers, etc is what is really required to truly optimize for something like a tick data store. Forget managed language access, you'll leave 30%+ on the table at least before hitting your database or utilizing what you get from it. Unmanaged calls, pointers, pinning, and advanced performant-oriented data structures are where the true speed comes from. Otherwise, you'll give back most, if not all, of anything you gain from database optimization. So essentially, the database can be tuned to the hilt but the way you load and use that data must be extremely efficient and fairly low level when your dealing with huge amounts of data like a tick store.
I hope that helps and is clearer that, say, mud. I wish you and your devs the best of luck. This is no one man show when done right but the capabilities it'll yield break all restraints and allow quant level strategy development and testing. I have no doubt there are other ways (perhaps even better) of accomplishing a tick storage system. I am however offering insight on how I did it in an actual enterprise grade implementation,nit just based on a white paper or opinion.
Oh, one point I didnt address is my usage. I actually run my tick storage locally instead of in the cloud for maximum performance. I don't want to be limited by (although 1Gbps) my Internet connection. My raid setup is optimized for read operations so I never wait more than a matter of seconds for as much tick data as I need for testing.
Broker: NT Brokerage, Kinetick, IQFeed, Interactive Brokers
Trading: ES
Posts: 159 since Dec 2014
Thanks Given: 40
Thanks Received: 166
@stocksharp brings up a great point of you must consider the end user. Do you need multiple concurrent connections? Is it just you? If it's just you, I'd agree to go with a more human readable format like CSV or json.
As far as operations performance, that is extremely (I'd argue entirely) dependent on design. For example, one of my benchmarks was loading AND replaying the entire NASDAQ 100 plus the top 6 futures contracts, every single tick for 4 hours during peak volume (before Chicago lunch). I am well under 10 seconds on my run of the mill i7 2600K, 32GB RAM, and 2 SSD in raid 0. May not sound all that great but my system is not overclocked and this is just under 5GB of data. This also includes doing numerous logic checks to ensure data integrity and proper sequence. The best part was this pipeline scaled 1:1 based on system performance so a system which was 50% slower, performance was half, systems that were 5-10x faster than my workstation were 5-10x faster. Design, design, design. It'll "SHOW YOU THE MONEY!!!"
I'm going to address a few random things brought up in this thread.
1. JSON
Definitely don't. JSON is the only serialization format that I would absolutely recommend against.
JSON doesn't have explicit typing (hence no bit alignment), which inflates your storage requirements and makes compression ineffective. Parsing JSON is clunky and slow in most languages (C++, Python, bash). There's no clearly defined standard so you have to specify properties in an application-specific header format, which is troublesome to maintain. And because of the way it accepts nested braces, writing a streaming application that consumes JSON downstream is a pain though not impossible. JSON is an OK serialization format for configs, but not for market data.
2. TeaFiles vs CSV vs Feather vs Mongo (Arctic) vs Influx vs Postgres vs MS SQL...
This is the most useless debate ever. You can't wrong with anything (except JSON) when you're talking about OHLC data for <500 symbols even going back 80 years. For example, the CRSP database stores 80-90 years of OHLC data on 10,000+ symbols and does its job entirely on a relational DBMS and commodity hardware. It's not fast, but it gets its job done. Focus on ease of use and familiarity rather than performance or storage requirements.
It costs 1k~ to get a PCIe storage device that bumps even the most naively designed SQL database into the 10^5 TPS region. By contrast, it takes weeks of effort to design a scalable schema and do some CI to collect data points on what indices you want. It takes weeks of effort to install an exotic DBMS that you've never used before, familiarize yourself with its driver/DDL/QL and configure it for production use. If you even have the extra cash to be trading, surely you have a reasonable flow of income that a few weeks of your time is more valuable than $1k to you.
The time I'd start thinking about performance or storage optimizations is when (1) you are clearly I/O bound and (2) you have multiple hosts consuming the data at the same time. That means even if you have a single 40+ core workstation, it's still too early to start thinking about optimizations.




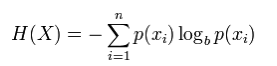



 No really. Most of all operations - select batch (for example, to do some
No really. Most of all operations - select batch (for example, to do some